Jonny currently works as a Senior Machine Learning Engineer at Spotify working on improving the search functionality on the app. Prior to this he was a data scientist at Deliveroo working in several different areas including personalised restaurant recommendations on the consumer app, menu classification and fraud detection. Before that, Jonny also worked as a data scientist at News UK where he was responsible for building machine learning models to aid editors with the creation and promotion of news articles. Jonny previously played American football for 9 years, and now is a keen functional fitness competitor. Jonny has a Master’s of Mathematics degree from the University of Southampton and a DPhil from the University of Oxford in mathematical x-ray crystallography. Talk Description: When a Spotify user types a query into the search bar it sets off a cascade of algorithms which ultimately ends in the user being shown a set of music and/or podcast results. This cascade of processes can be very complex as we must try to understand exactly what the user is looking for and choose a handful of results from a set of 10s of millions of potential options. As more and more items are added to the Spotify catalogue, from music to podcasts and soon audiobooks too, the Search team has increased in size and scope to try to tackle the growing challenges. In this talk I'll give an overview of the components of a typical search system and explain some of the challenges that arise in search systems. Then I'll talk about some of the new algorithms that we've developed over the last year that have led to huge improvements in Search quality. Finally, I'll outline some of the general lessons that I've personally learned with building machine learning models.
Hello, Is It Me You're Looking For? Improving Spotify Search


























Auto-generated transcript - may contain errors. Tap a timestamp to jump the video.
Hey. Hey. Alright. Hello, everyone. Wow. Everyone's here. It's amazing. Yeah, it's a privilege to be here. For those that don't know me, I'm Johnny. I'm a senior machine learning engineer at Spotify, And I've been there for almost two years now working on search.
And so we're, yeah, what I wanna do today is talk a bit about search. So this is what we'll be covering. When I joined Spotify, I'd never worked on a search problem before. So I didn't actually know what components were involved in it.
So what I wanna do first off is is introduce the search problem. How do we solve search when someone types a query? How do we get those results? And then once we've covered that, I then want to move on to why search is hard. Alright.
So it's gonna be easy to think, you know, if someone types Drake or drizzy, you know, he should show Drake. Like, why do they pay me to go and try and help you get the right results? So I want to explain why it's hard.
And then then and only then once you've covered how search works and why it's hard, do I want to cover what we've been doing in search over the last year to improve the results. And then finally, I have to admit every time I've practiced this presentation at home or whatever, I have never in allocated thirty minutes gotten to lessons learned.
So we'll just play it by ear. Like, it's enjoy the ride. Enjoy the ride. We'll we'll see if we get there. But yeah, this is what we'll cover. So introducing the search problem. What is the goal of search? So if there are any academics in a room that have covered this sort of section here, you might hear information retrieval.
That's what they call it. And you might cringe at my definition, but I'm the guy on stage. I get my own definition. So this is how I'm gonna put it. So given a search query, Right? We need to provide the user with the most relevant results.
Now, relevant is in quote marks here because it's gonna be context dependent. It's gonna depend on who you are, what music you listen to, how much milk you added to your coffee this morning, you name it. It's going to be anything. So we don't actually know what is the most relevant thing.
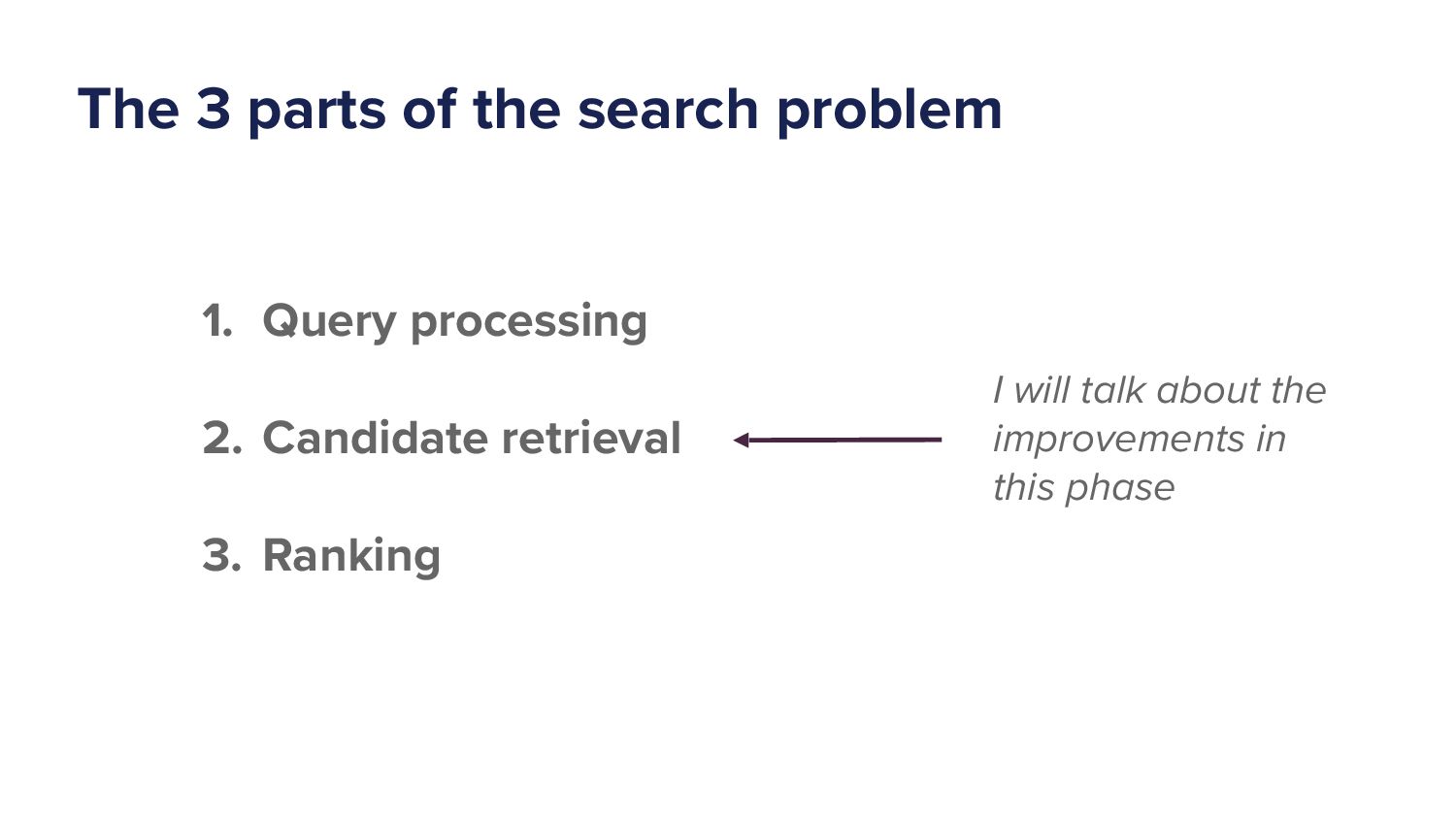
Everything we put in front of you is a best guess. Right? So that's what we're doing. Given that someone types a query, we wanna put in what we think are the most relevant items to show you. So given that, right, we can then move on and say the search problem can be divided into three main parts.
Right. And what I'm gonna do over the next five, ten minutes, and I I can talk a lot from. So five, ten minutes is we'll we'll see how much I decide to waffle. I'm gonna cover these three things. So query processing, candidate retrieval, and in ranking.
They're they're the main components of any search system. Not just me and my boy lion or Ritchie, not just Spotify. This is anyone. So whether it's Google, whether it's, any e commerce site, this is how search will be set up. So first off, what is query processing?
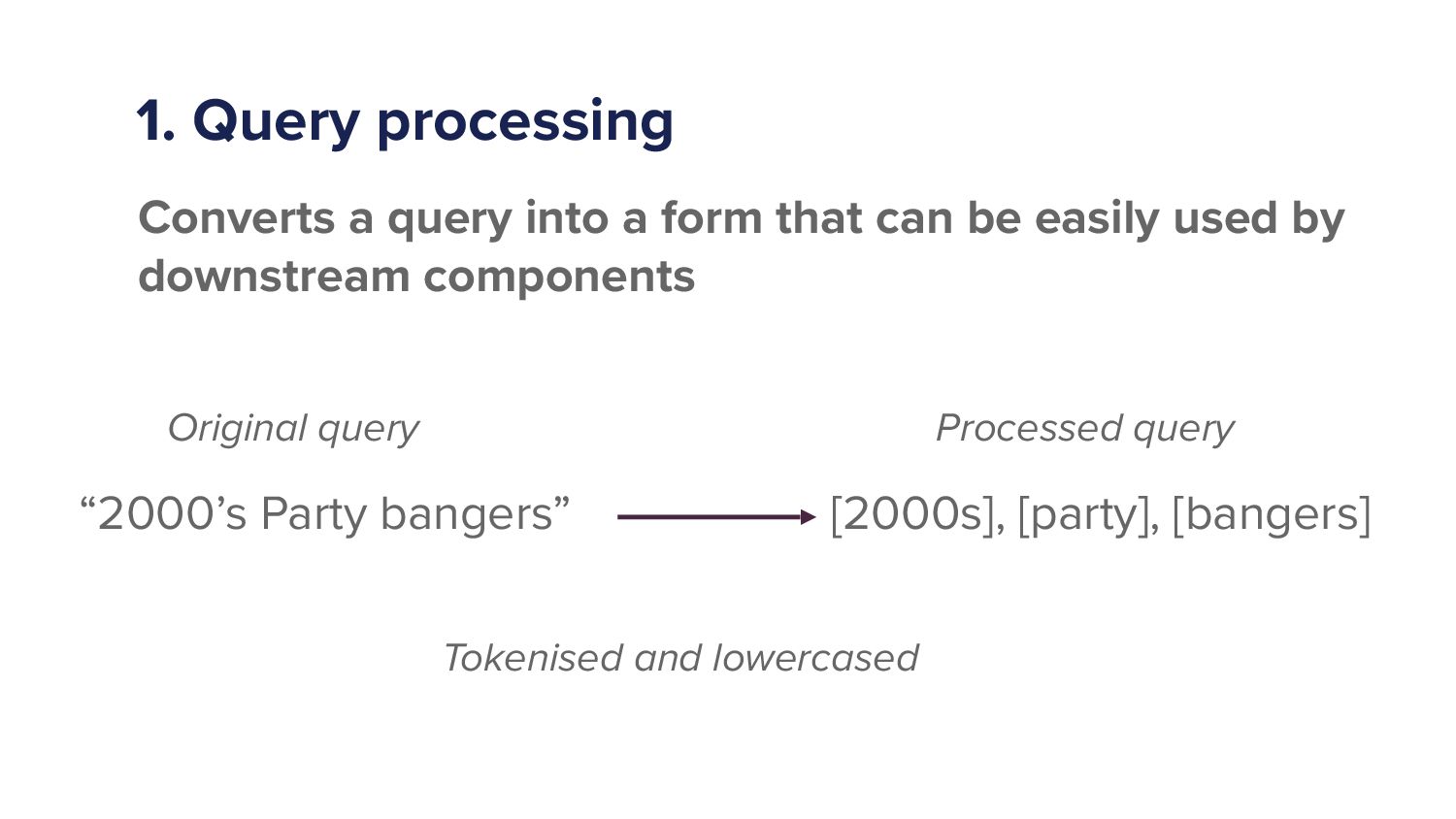
Well, simply it's we're going to convert a query into a form that can be easily used by downstream components. So what do I mean by that? Let's say, on the left hand side, I type a query. I put in two thousand's party bangers.
You know how you roll. I want to go to some naughty music. I want to do my thing. Right? That's that's what I do. Right? A computer may not actually understand what you mean by that. Right? Computers, ones, and zeros. So we need to process that.
So how might might we do it? We might split that query up into different words. We call that tokenization, right? So we'll split it up into different words. We will also lowercase some things. So there's a capital p in party in the original query.
We'll lowercase that. Right? So it's all standardized there. We might get rid of apostrophes and recall that normalization. So we're gonna process this query. Right? That's what we'll do. And when we do that, this can these things can now be used better by downstream components.
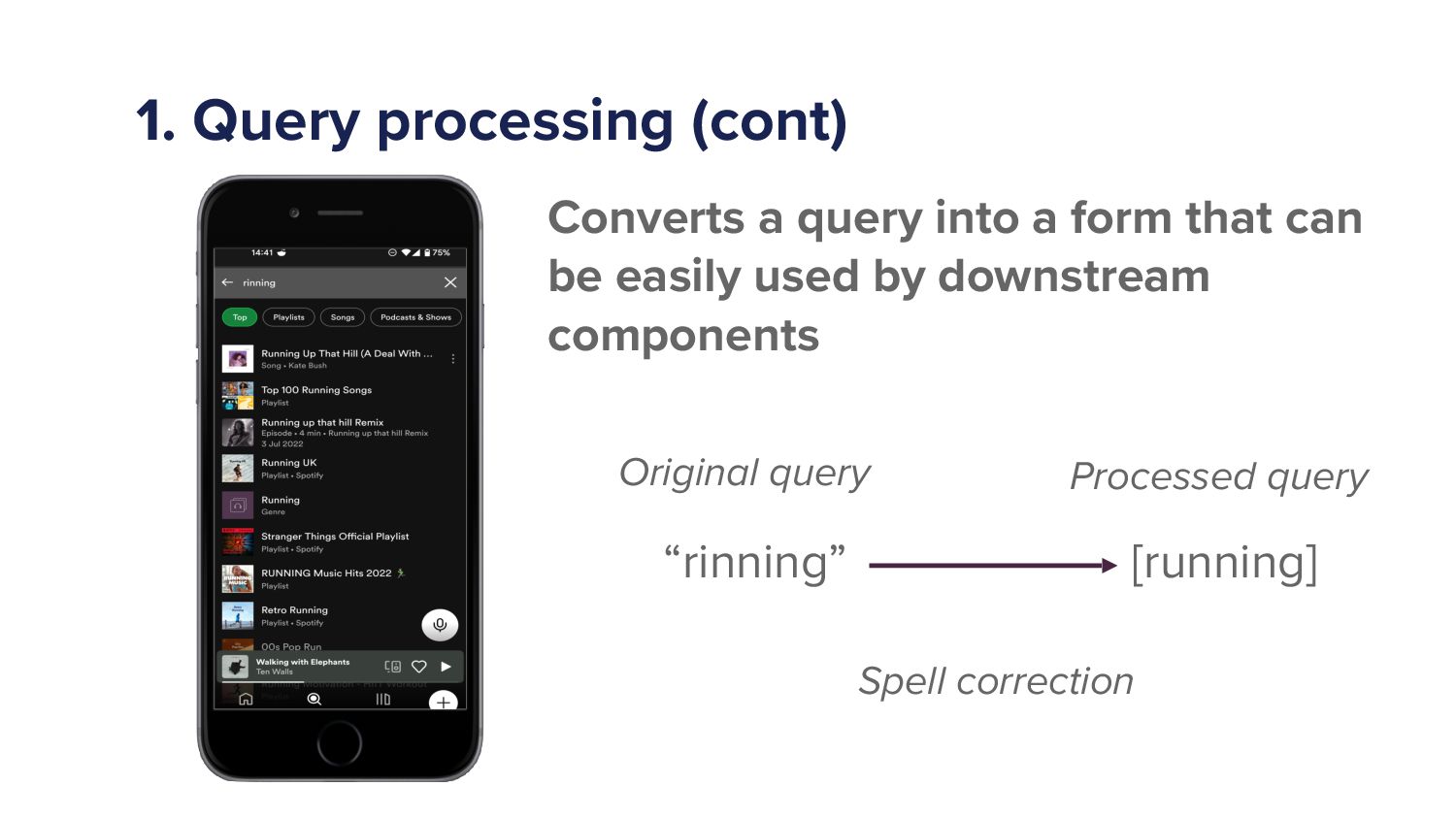
Right. Another quite important query processing step, which isn't done by all search systems, and you'll probably notice this, is spell correction, So I is next to you on a standard English qwerty keyboard. So you'll often see a misspelling ringing instead of running. So one form of query processing might be spell correction.
Right? You'll notice, search engines that probably don't incorporate this because you might get when you type into a search engine, a misspelled thing, you might get zero results. That will be a search engine that isn't doing spell correction as part of its query processing.
Right? So different search engines will have different ways of doing their processing. Alright. And this is something that, we implemented in Spotify a few years So, yeah, the the spell correction. So you'll notice there I've put running into the search group. I should tell you all all of these searches I made about a week and a half ago.
Know, I had to get I had to get some images and stuff on on here to make it nice. So I've put running in and you can see the first track, you know, Kate Bush, you know, a great track. Come on, running up that hill. You gotta do a thing.
So, yeah, that's query processing. Alright. That's the first stage. That's the first stage. The next stage is what we call candidate retrieval or candidate generation. So we've now got a query that we've put into a form that's easily usable, right, by by these downstream components.
Alright. But now we need to take everything that's in our catalog. So at Spotify, we have hundreds of millions of stuff in the catalog, whether that be episodes, part of of different podcasts, we've got music, artists, album, all those things. So our our catalog is hundreds of millions.
If you're Google with the, search index on web, it might be billions. If you're a smaller e commerce site, it might be hundreds of thousands. Right? But you want to take everything from your catalog and you want to narrow that down into say a few hundred things.
Right? So this is what we're doing. The candidate retrieval stage is from hundreds of millions down to a few hundred. Alright? That's that's roughly what we're doing. And this is for about a year and a few months, a bit over a year, this is exactly where I've spent my time.
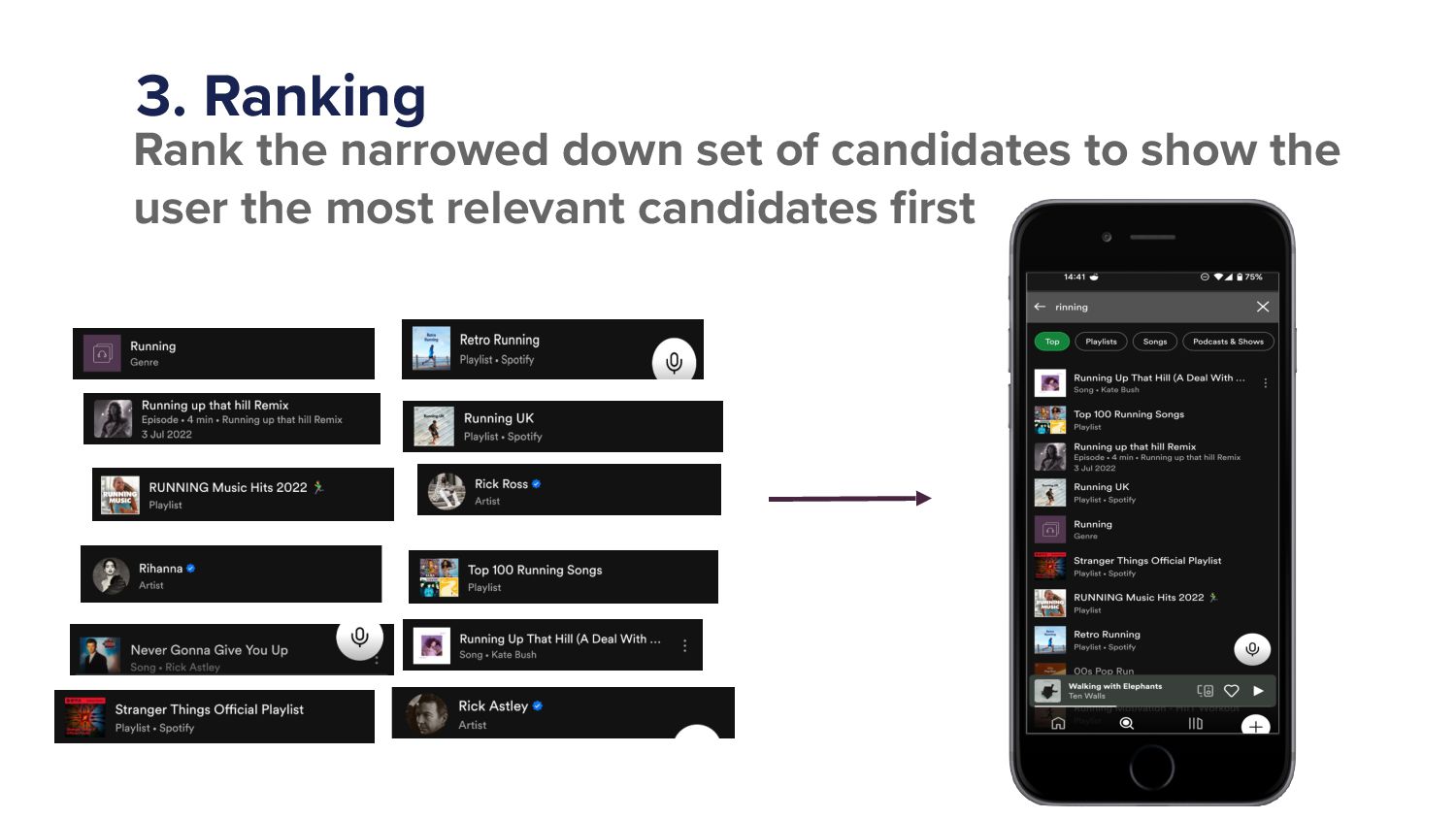
Right. This is where I've been writing algorithm. So when I continue talking about what we've done, It's gonna be in this area here, candidate retrieval. Right. But the next stage, once you've narrowed it down to a few hundred, We then need to rank that. Right.
We then need to rank it so that the results that you get on the phone, you probably see probably see the first five to ten. Right? We need to make sure they're the most relevant out of those out of those few hundred. Right.
And the reason we narrow down to a few hundred is because you'll notice with Spotify search engine, if you use it. Alright. We give you results on every single key stroke. So the time it takes for your keystroke, a few milliseconds, we have to do all of those three stages.
So we have a latency constraint when we're doing search for Spotify. Need to make sure that we do query processing, candidate retrieval, and ranking in milliseconds so that we can provide you with with those results. If you're, let's say, a web search engine where you type your full query and then you press search, like in Google search, you don't need to do that, but you still want everything to happen in milliseconds because if you're waiting five seconds for your results, you're you're you're gonna go nuts.
You'll choose something else, dot dot go or or something like that, or bing. Right. So they're the three stages. All search systems will have some form of those three stages of search and that's how it works. That's how we get stuff in front of you.
You know, And so as I said before, this is where I'm gonna talk about, that arrow is out of place. Come on. That should be right on candidate retrieval. Yeah. That's my fault. But yeah, so that's where I've spent most of my time, candidate retrieval, and that's where I'm gonna spend my time talking about the improvements today.
But we've got teams working on different parts of this. Different parts of these these parts of search. So I've covered what search is about. I've covered the the three components and I've told Gina, someone types in a query, we gotta get these results.
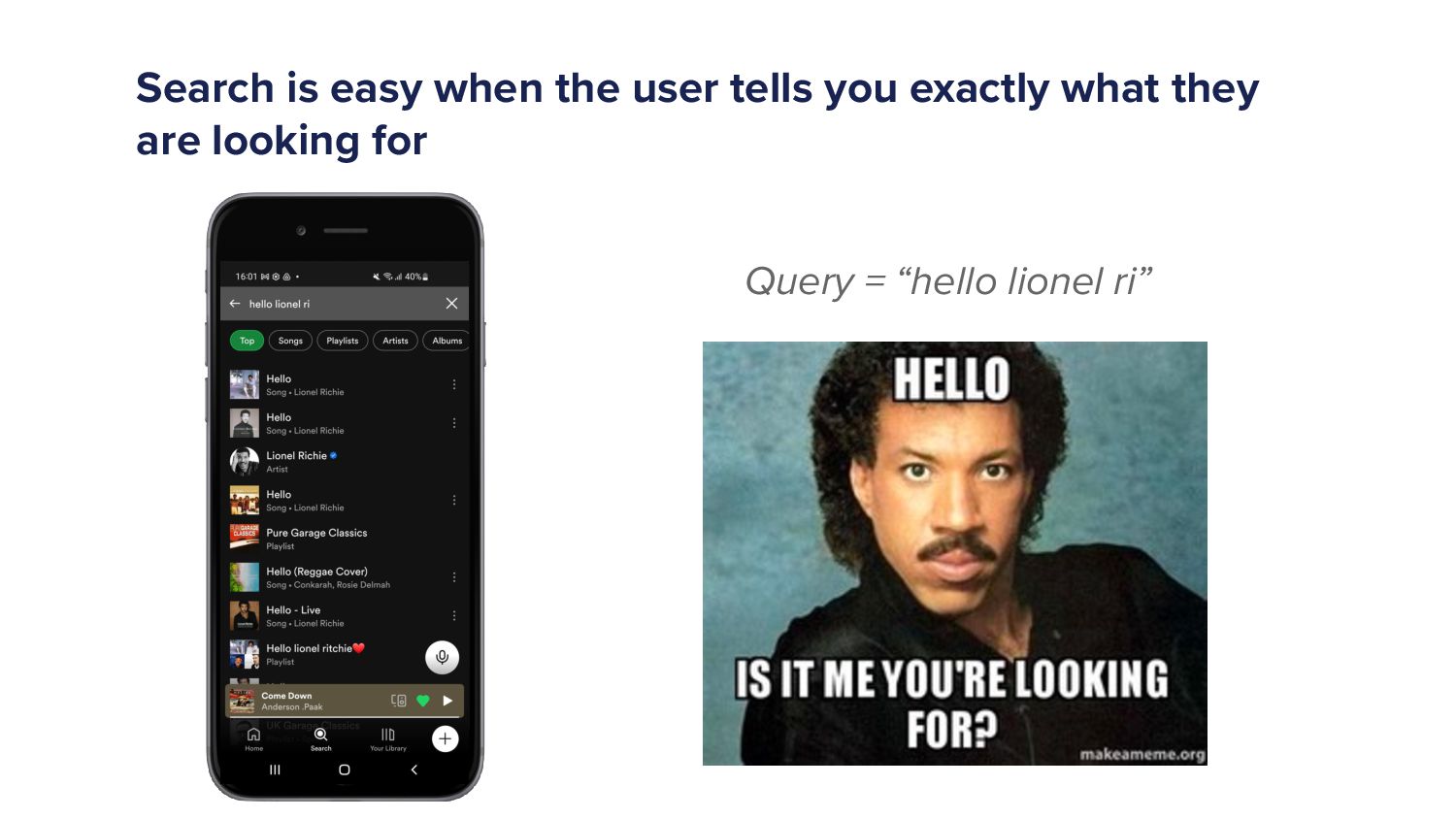
We gotta get these results. So why is search hard? Why is it hard? Well, search is easy when the user knows what they're looking for, and they tell you exactly what they're looking for. So you know, here we've typed in the query Hello, lionel Ritchie, you know that song?
Hello? Is it me you're looking for? I had to do that. I had to do that. And the reason I had to I was when I was when I was writing this talk, right? My partner said to me, if you sing on stage, I mean, it's so cringe You know what?
She's sitting right there. So I had to do it. I had to do it. But that's my boy, lionel Ritchie there. Yeah. So if someone types something like that, a query like that, we know exactly what you want. I can stick it at the very top. Of the of the search results.
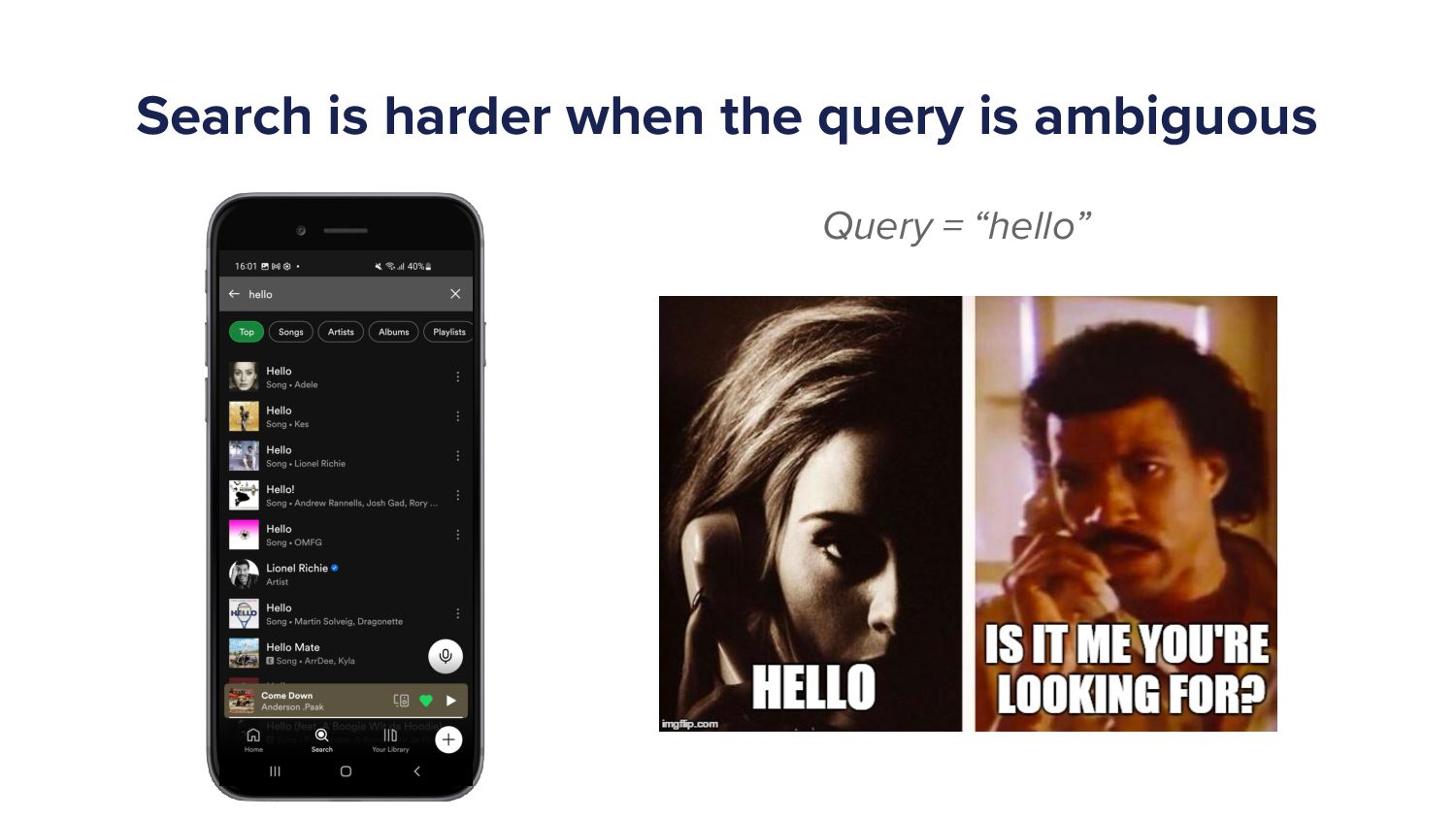
So you'll see at the very top, the result is hello by line or itchy. Search gets a bit harder when the query is ambiguous. If someone only typed hello, what are they looking for? You can see so many different songs here, all hello in the results.
You know, Adele had a hit recently, hello? What is the user looking for? The user might know what they want, and this is why I say com the the context is important. The user probably knows what they want, but from the query, do I know what you want?
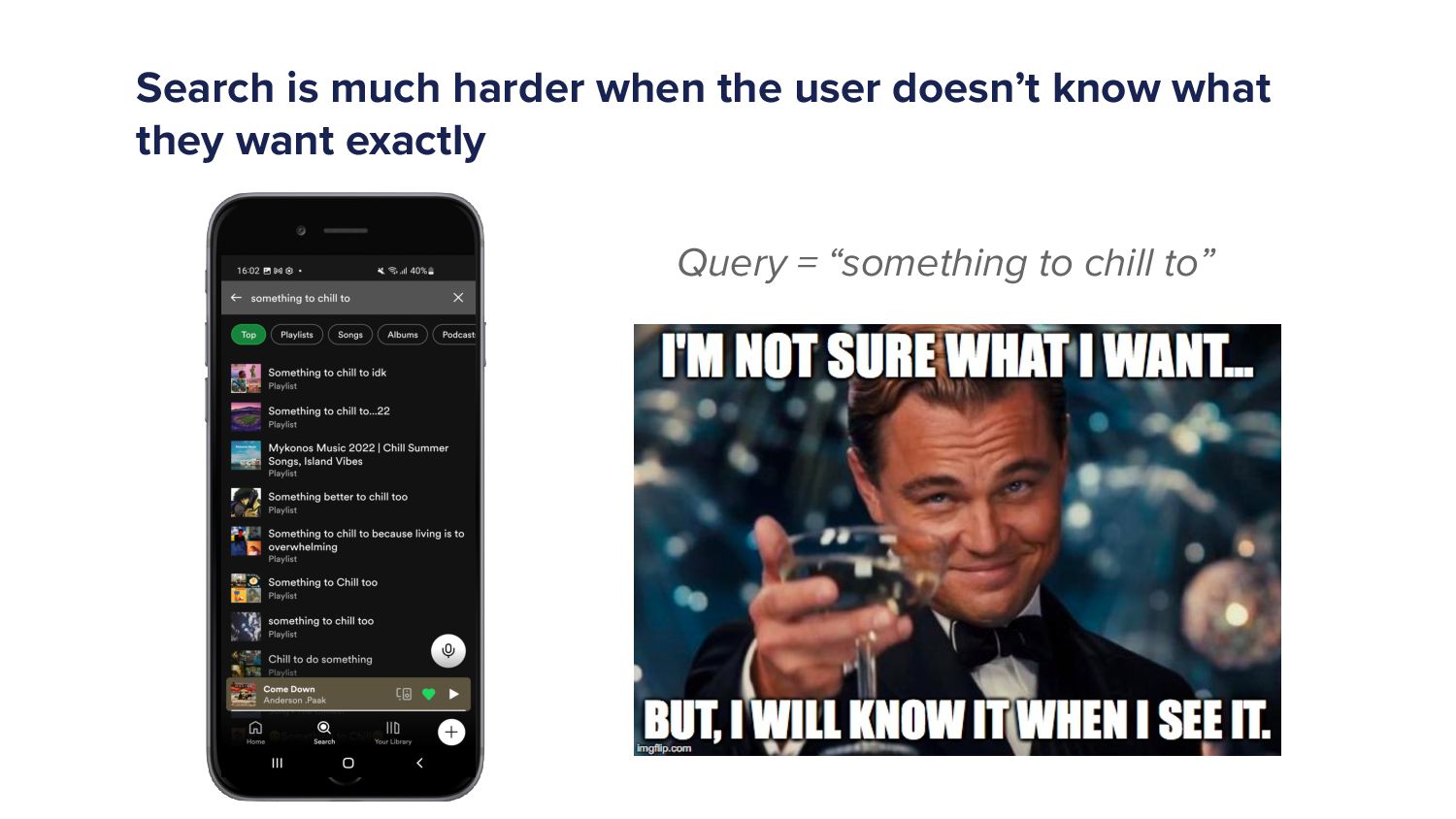
No. It's ambiguous. Such is even harder when the user doesn't know what they want. When they don't know what they want, So sometimes they'll just come and just be like, ah, someone chill too. Please, Spotify. Give me a sign. Hey. And so here's the the results something to chill to.
I'm pretty glad the first result there is something to chill to. I don't know, which is a playlist. I I think I think that's a that's a pretty good result. I like that. But yeah, so search can be hard if if the user doesn't know what they want.
And then, so Spotify isn't just doing music. A lot of it is about music, but now we're into podcasts, people search differently for podcasts because podcasts are very different types of content. Right? A user might just say something about that latest on political, unrest.
What is latest? Is it the last hour? Is it the last day? Is it last week? Right? Political? Where? Is it national? Is it international? Is it local? I don't know. So there, now we're we're into a land where these queries, although the user might know what they want at this stage, it's very hard to to have a very, singular definition of exactly what they want.
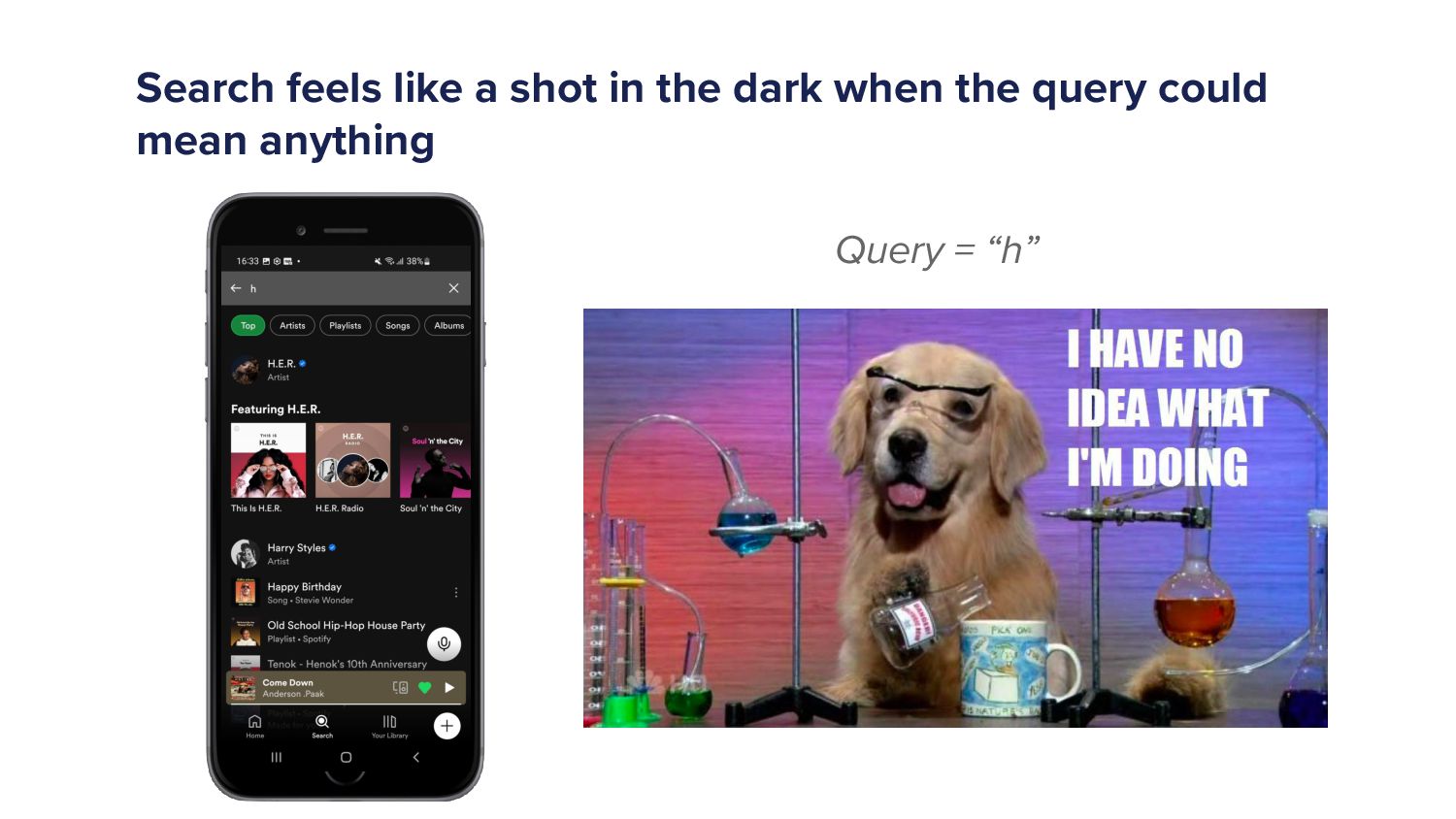
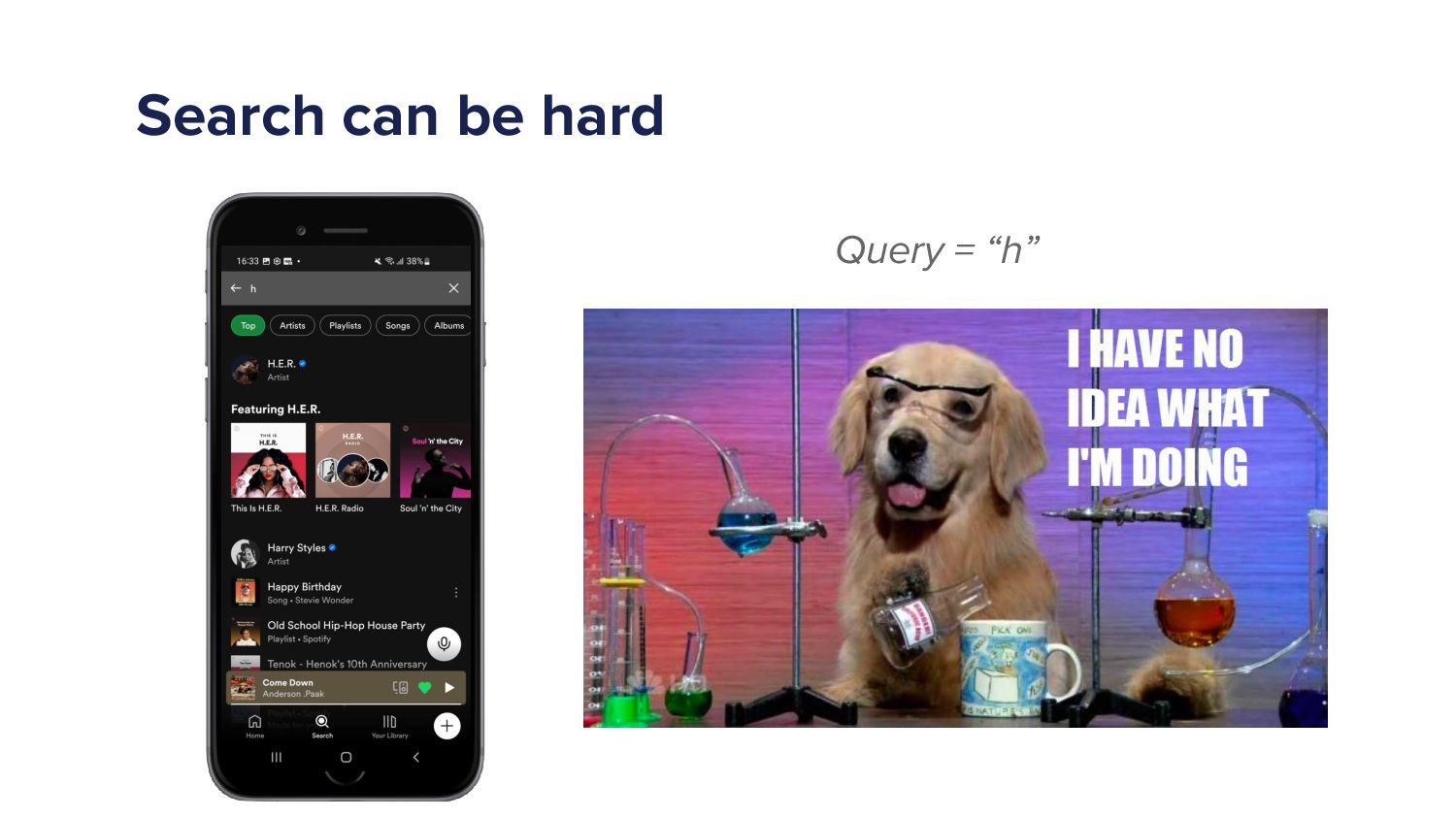
And finally, I said we have to provide results in every keystroke. Every keystroke. So if someone types it at h, Gonna give results. Yeah. I didn't know what did. So, yes, search can be hard. Search can be very hard. So hopefully, that has given you some idea about, How search works, so how the systems might be built to make a search engine work to provide you with results.
And that's for any company building a search system, but I've also, hopefully, with some examples, shown you why search can be hard. Right. It's easy if you know what you want, and you can tell the search engine exactly what you want. But when you can't tell the search engine what you want, or or you don't, then it's very difficult to work out what is the most relevant thing to or what are the most relevant things to show.
So what have we been doing in search at Spotify, over the last year to improve this. So Reminder, three parts of the system, query processing, candidate retrieval ranking. We're gonna talk about candidate retrieval, and that is about narrowing down to a smaller set of relevant candidates.
Right? And we have to do that. As I said, we had latency constraints, we provide results in milliseconds, So we narrow it down to a few hundred because that's what we can rank in a millisecond time scale. Right? If you've got a bit more time, then you might narrow it down to a few thousand.
So the amount you narrow it down to is specific to your your company, your business problem. But we need to do a few hundred. Alright. So what is the most intuitive way of narrowing down candidates to from hundreds of millions to a few hundred.
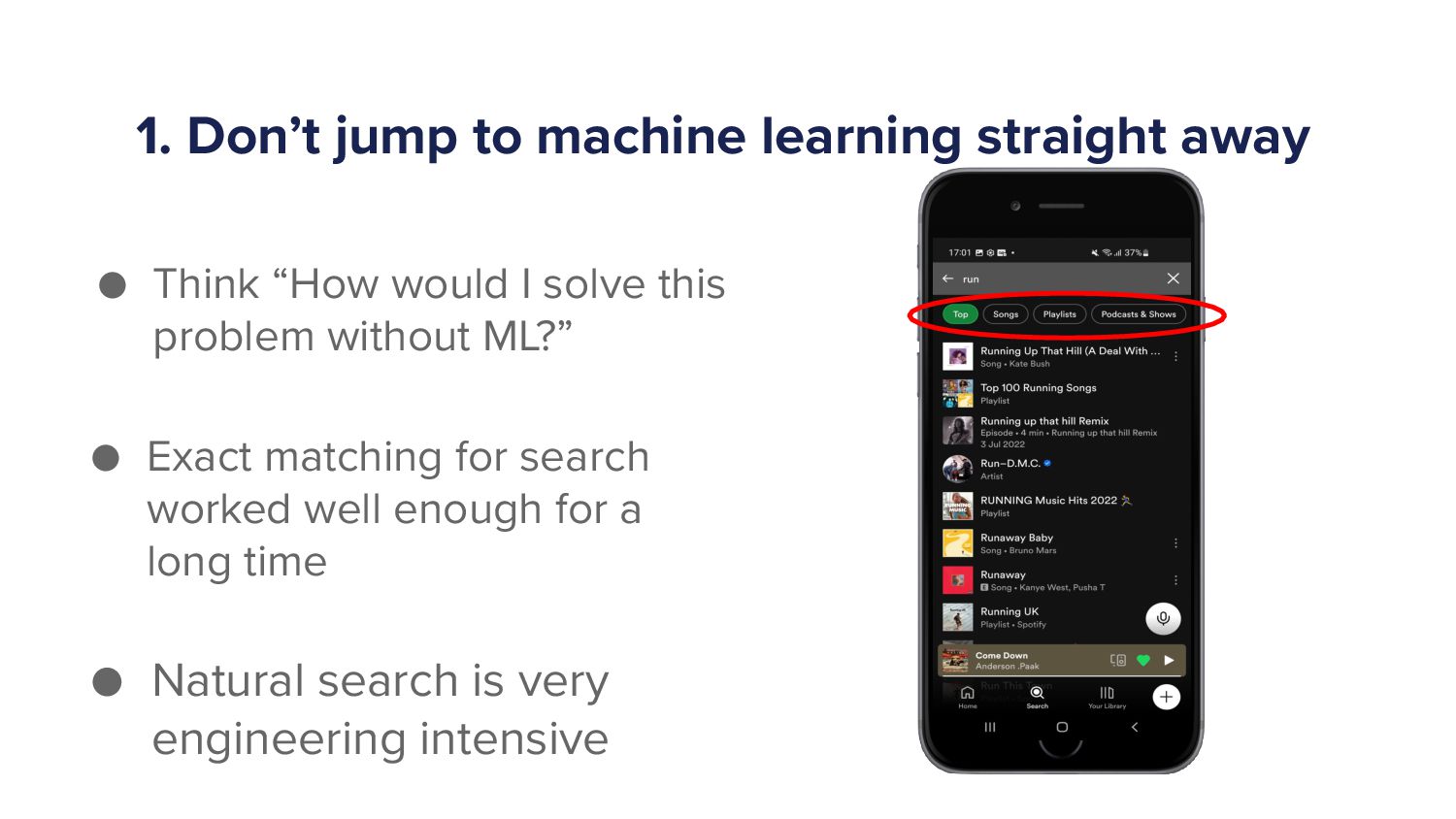
So the most intuitive way you can think about is just word matching or prefix So what do I mean by this? So in the results there, in the example, I've typed the query run. Right? That's all I've done. Just type in a query run.
So I can get all candidates that contain the string run. They're likely to be relevant. So the fourth result down is run DMC. I think if someone types in run, then run DMC is the fair enough result to to show. That's if I do exact match.
If I do exact match, run is in run DMC, but what about run as a prefix? Run is a prefix of runaway or running So I might also return candidates where run is a prefix of things in a title and a metadata. So this is the most simple, basic way you can narrow down to a bunch of candidates.
And this is likely if you were a a company where to build a search engine from scratch, this is likely the the first thing they'll do. This is like how all search engines will have some component of this, and we still have a massive component of this at Spotify.
Right. But there are limitations of doing prefix matching. Alright? So query something to chill to. There aren't gonna be too many things where that is an exact match, or a prefix match to, or latest on political unrest. And this is where query processing comes in.
So maybe if I split those up into different words. I do some tokenization, then I might do some exact matching or pre fit matching on something. And then I might do it on chill separately and things like that. So I can try and do something a bit better with that, but then you still have a problem.
So with the example, ringing, even if I spell correct that to running, even if I spell correct that to running, How do I get this playlist? Stranger Things official playlist? Right. It's not a prefix of anything in that title. Right? But it might be that someone who typed running, liked running up that hill by Kate Bush, knew it was in stranger things, and wanted that playlist from stranger things.
So how do we get this? That's what I'm gonna tell you about now. Hey. Yeah. So we built two systems over the last year to improve this candidate retrieval, process. One's called crowd surf, The other's the other's called natural search. I'm gonna cover the next, oh, what?
I'm going quicker than I thought. We might even get to listen to learn people. We might do this. So I'm gonna cover these two, systems, and maybe even get to lessons. Lord, man, this is good. This is good. So crowd surf. This is the one I've spent most of my time working on.
So this one, how does it work? How does it work? What this is a candidate retrieval system? How's it work? So let's say the user wants to come and type in some characters, right? They type in r r I r are, blah, blah, blah, blah, blah, blah, they type in re re, essentially.
Alright. But the reason I've put in a different character strokes is because, as I said, Spotify, we give you results in each key stroke, So we log every single character stroke. So we have all of these. So these four things. So you type in Riwi.
Most of you in this room, maybe all of you might know who that user is looking for. It's an alias for Rihanna. Right? But if that alias is not in our metadata for that artist, then we won't return a result for that. We won't return Rihanna.
So the user doesn't see the result they want. So then they're like, man, I gotta delete some things. I'm going to delete some things, and then I've got to type in Rihanna, and then I'm going to click on Rihanna. So there we go.
They delete some stuff, type Reanna, then click on Reanna. That's what they do. So now we're looking at a single user's behavior. This is their behavior on the app. Right? So what we would do, we look at this what we call sequence of characters, and then we would group every single unique sequence of those characters, so they're all on the on the left there, and say that Rihanna must have been a relevant result for all of those queries that were typed.
Must have been. And the assumption that we're making, the implicit assumption we're making about the user is that they had the same intent throughout the entire sequence. Right. So this is the the core assumption of this system. We think you have the same intent if you're doing the same thing within, a certain amount of time, right?
And and the way we define it is as long as you do keystrokes within twenty seconds of each other, you're still probably thinking about the same thing. Alright? So all of those would be linked to Rhianna, and then forget about a cloud big table thing.
We basically store it in a database. It doesn't matter what it is. Right? We're just thinking cloud based. It's some database. We basically associate you things. And the idea now is because we've put those together, if someone then types re-re-re- in the future, they will then get Rihanna.
So notice now, I don't need to know what the the title of a piece of content is. I have no I don't I don't care about that. All I care is that you made a query and you clicked on something. So now I can return things that don't match the the characters in there.
Right? Simple. You know, never machine learning in this part. Never machine learning here. This is simple stuff. Simple stuff. Just go to some logs. Right? Some SQL queries, get some data out. You know how we roll? Okay. But so the hard thing now is we have to extend this to multiple queries.
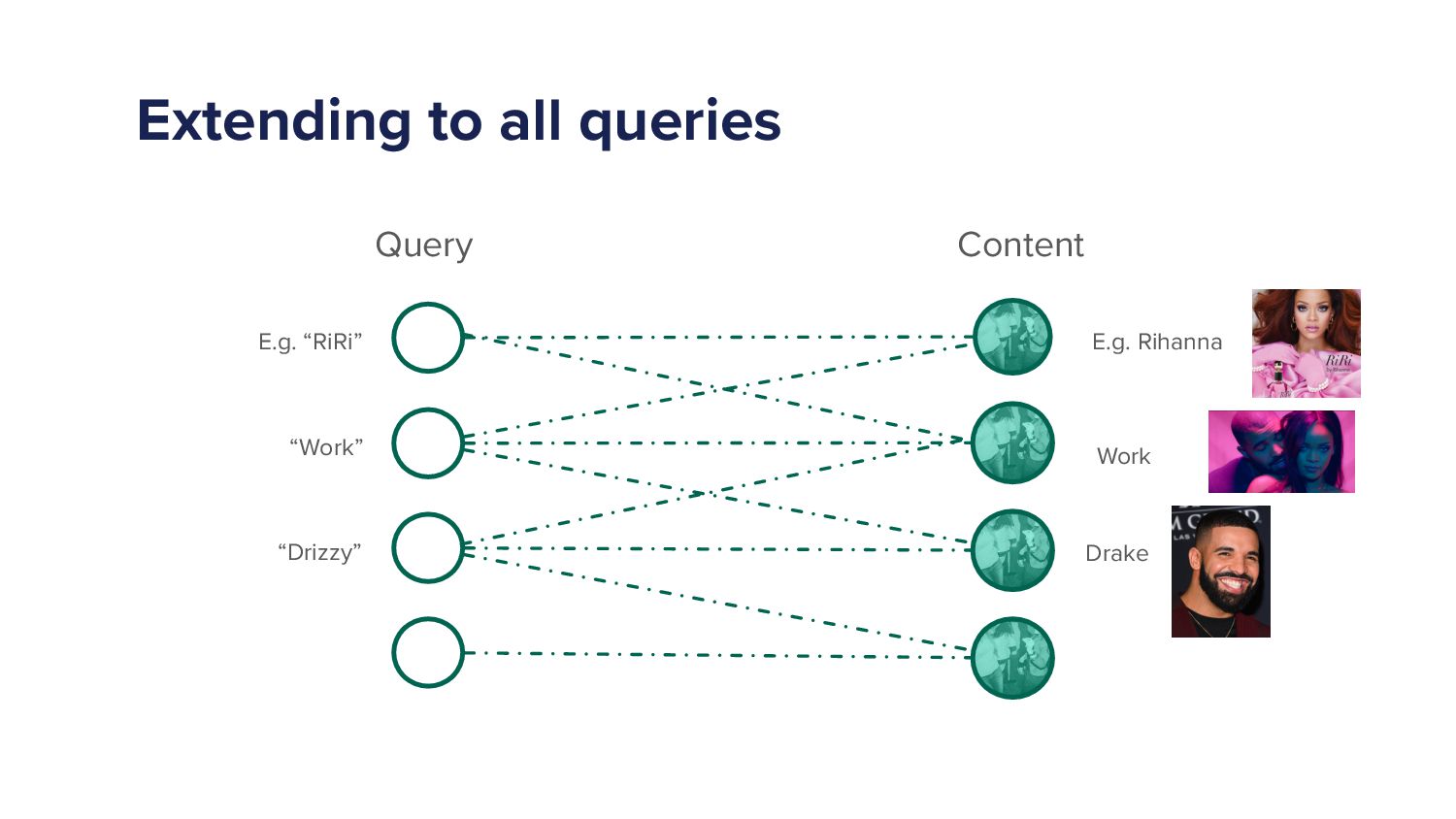
So that was just one. Rimi goes to Rhianna. But how else might someone get to Rhianna? Or or or what else might someone go to? So if someone types Ruby, they might not just want the artist to Rhianna, They might want the song work. You know, work.
Rhiana featuring Drake, let me see. Work. Work. Work. Work. Okay. So they they might want a song work. They might want a song work by Brianna and Drake. Right? But I also might type in the query work to get to that song work, or or they might type drizzy.
They might type drizzy and still want the song work, or they want Drake. So all of a sudden now, we have a graph of all of these queries, and all of these contents. And and if you get a graph like this where you get like two lots of circles on one side, and a lot of circles on the other side, we call those circles nodes, we call it a bipartisan graph for anyone who's in academia and and is doing this stuff on a very theoretical level.
We have a bipartisan graph and we have connections between the two equal edges. And what we now need to do is work out the likelihood that if someone typed the query Riri, what's the likelihood that or what's the probability that they'll click on Rihanna versus the probability that they'll click on work or the probability they'll click on Drake.
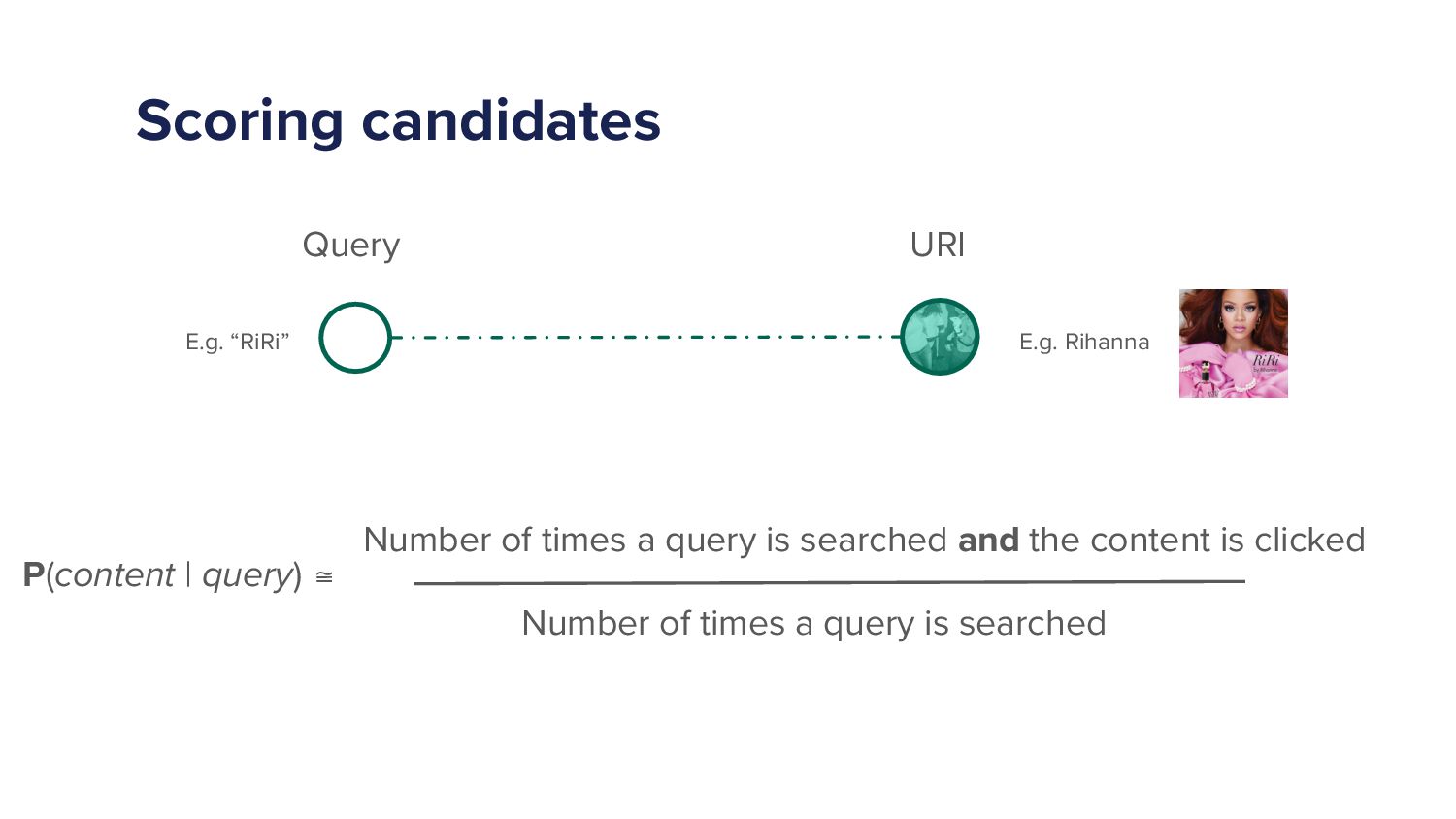
So we just need to work out the numbers on those edges, and then we're good. Then we're done. Because then I use the probabilities as my scores, for ranking and and giving the top few hundred. Because then I can I've got numbers. Right?
And I just sort by the top first few hundred, and then I retrieve all the stuff that I want. Right. So that's what we do. And so we just go back to our logs, and we say, okay. What's the number of times that someone made the query?
Ruby, and then clicked on Rihanna. Right? So that goes on the top. The number of times that happened, it could be a thousand. And in a number of times that someone just searched, made the query riri. So let's say it was two thousand times, and then I've got one thousand over two thousand.
Probability zero point five, zero point five. So then I've got probability zero point five that someone queries Ruby, they'll click on Rihanna. Done. Stick that out of database. Someone then searches on the Spotify app. We go to that score bang. We put it up there. That's it.
That's how it works. Alright. And and this literally is this the division. And we learn now how to do this in primary school. We don't do some primary school. We can do this. And that was huge for us. That was huge. We rolled this out this time last year.
Right? So now it's all it's in Spotify as in production. It happened last year, and the amount that people now had to type reduced so much. You don't have to type so many letters anymore. You don't need to reformulate from aliases because aliases are stored by this, by people's behavior.
So what we call search friction reduced massively. So this was huge for us. And then we increased the number of successful searches because no longer were people getting empty results, when they typed stuff, they were seeing things which they expected to see. So every every number went up for us.
This was I I've only put two here, like two things. Everything went up. It was brilliant. So yeah, we've we've got this in production right now and we're trying to improve the scoring mechanisms and and the associations, but yeah, that that's crowd surf.
That's ground surf. It's brilliant stuff. So I hope that was, the nice sort of understanding about one of our systems. Alright. So that's crowded. The next one, which we're now spending even more time on, and now most of my focus is on this system.
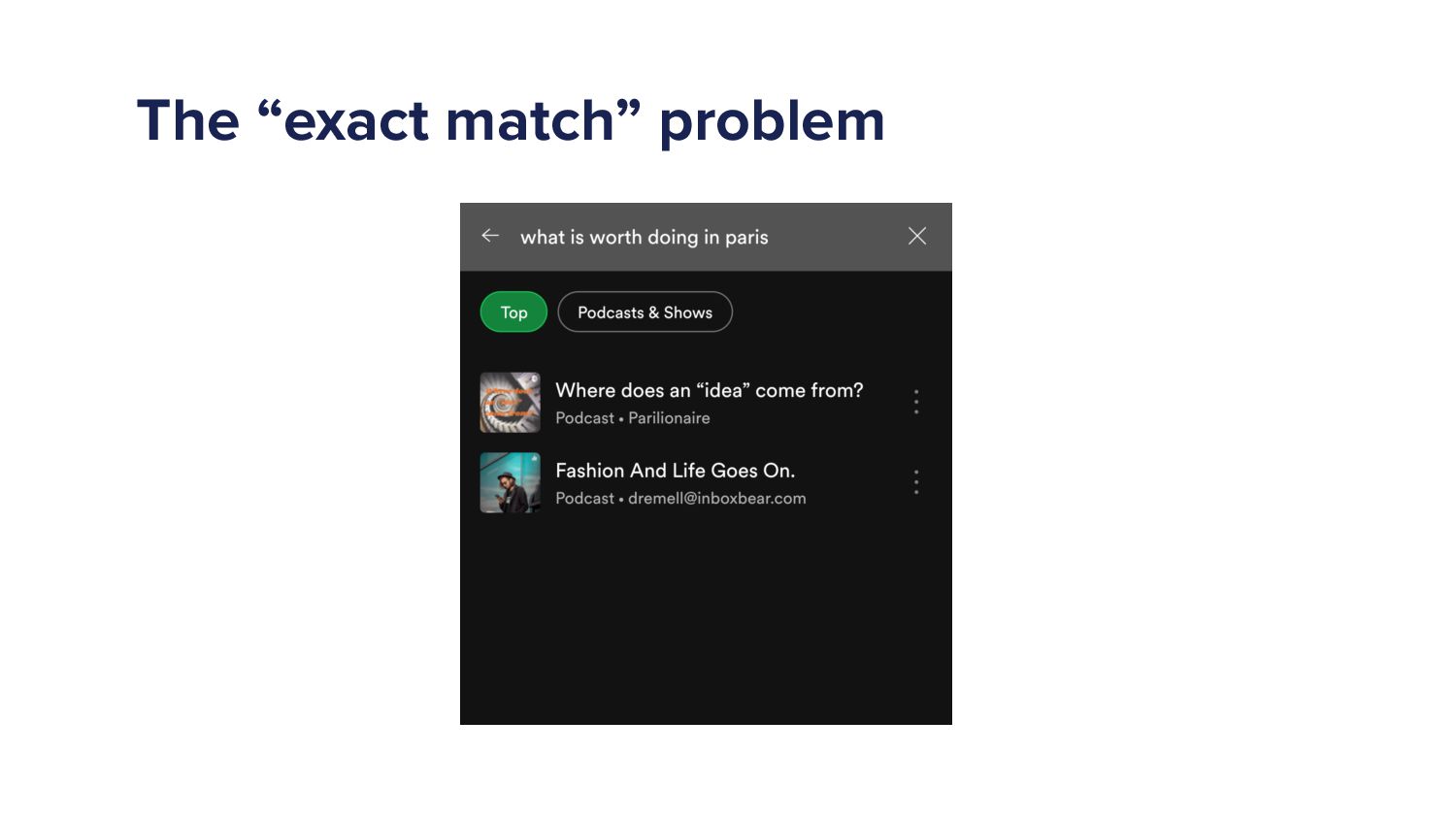
And even right now, while I stand here, the team are are working to improve this one, is called natural search. So why did we build this one? So we have the exact match problem, the exact match problem. Let's say someone types a query, what is worth doing in Paris?
This is what you would have if this time last year, if you'd put in Spotify, what is worth doing in Paris, this is what you probably would have got. Right. This is what we got when we didn't stick it in. The reason why I say this is what you probably would have got is there's some personalization on the ranking, so you might not get exactly the same results but this is this is what you'd expect.
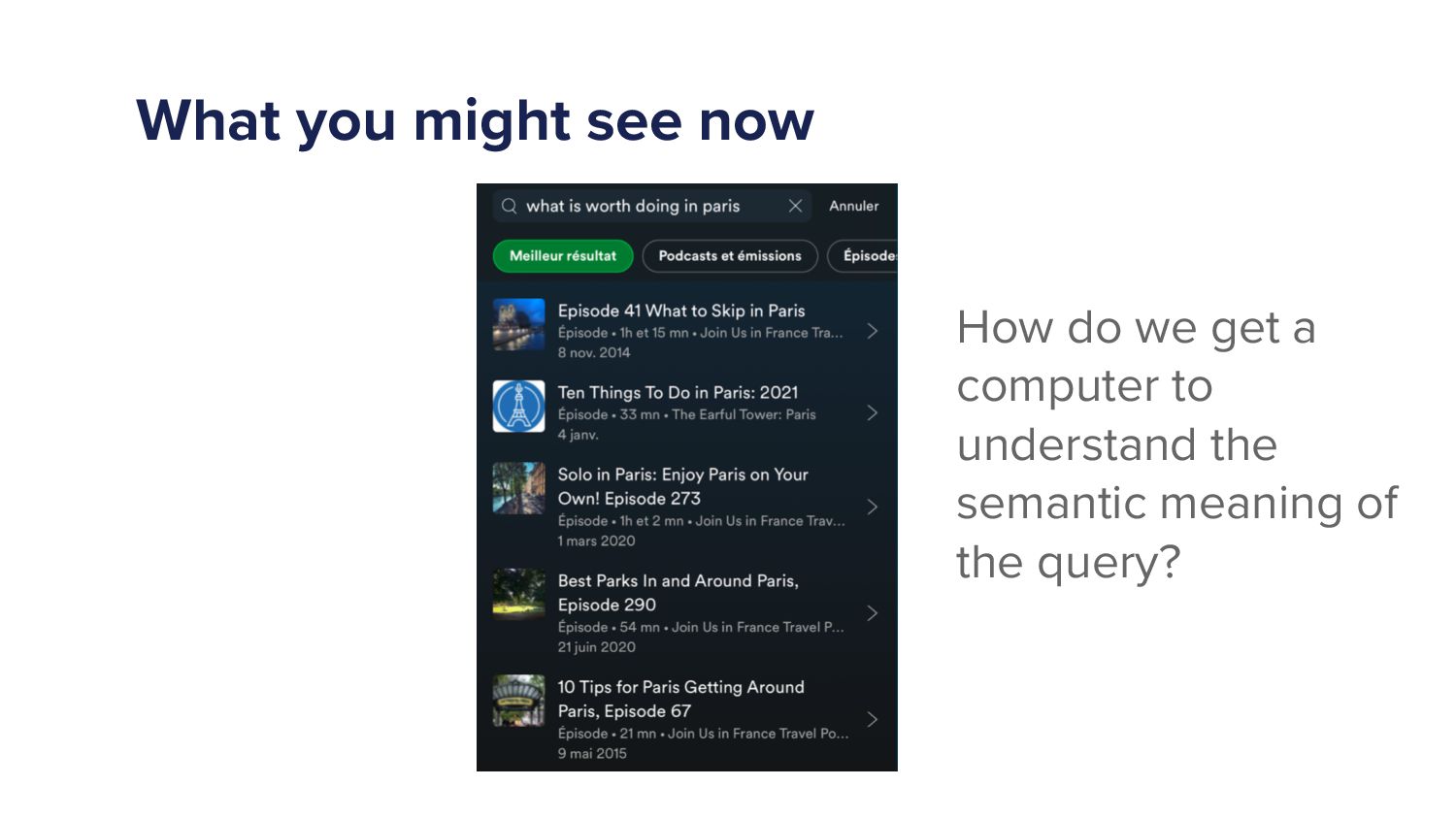
Not great. Right? What is worth doing in Paris? We know what the user means by that. We have some underlying semantic understanding of words, of language, the computer doesn't. So Yeah. The results are are are terrible. Today, if you type into Spotify, what is worth doing in Paris, you might see something a bit more like this.
So here, you know, top result, what to skip in Paris or ten things to do in Paris twenty twenty one. Right? Not perfect. It's twenty twenty two today. Why are we doing twenty twenty one? But so we can improve on some things, but What we have got is an algorithm that's, somewhat understands what the user is getting at.
So how do we do this? How do we do this? So this, this, we leverage things called, word embedding or send it to embeddings. So some of you may not know exactly what I'm talking about. So let me explain what it is. I'm gonna try and explain what it is at a high level.
So, This paper published by Google in twenty thirteen first introduced this idea, and since then, artificial intelligence in the natural pro natural language processing space has just blown up. Right. All these things that you're seeing now where AI is like generating all these text all comes off things like this word embeddings.
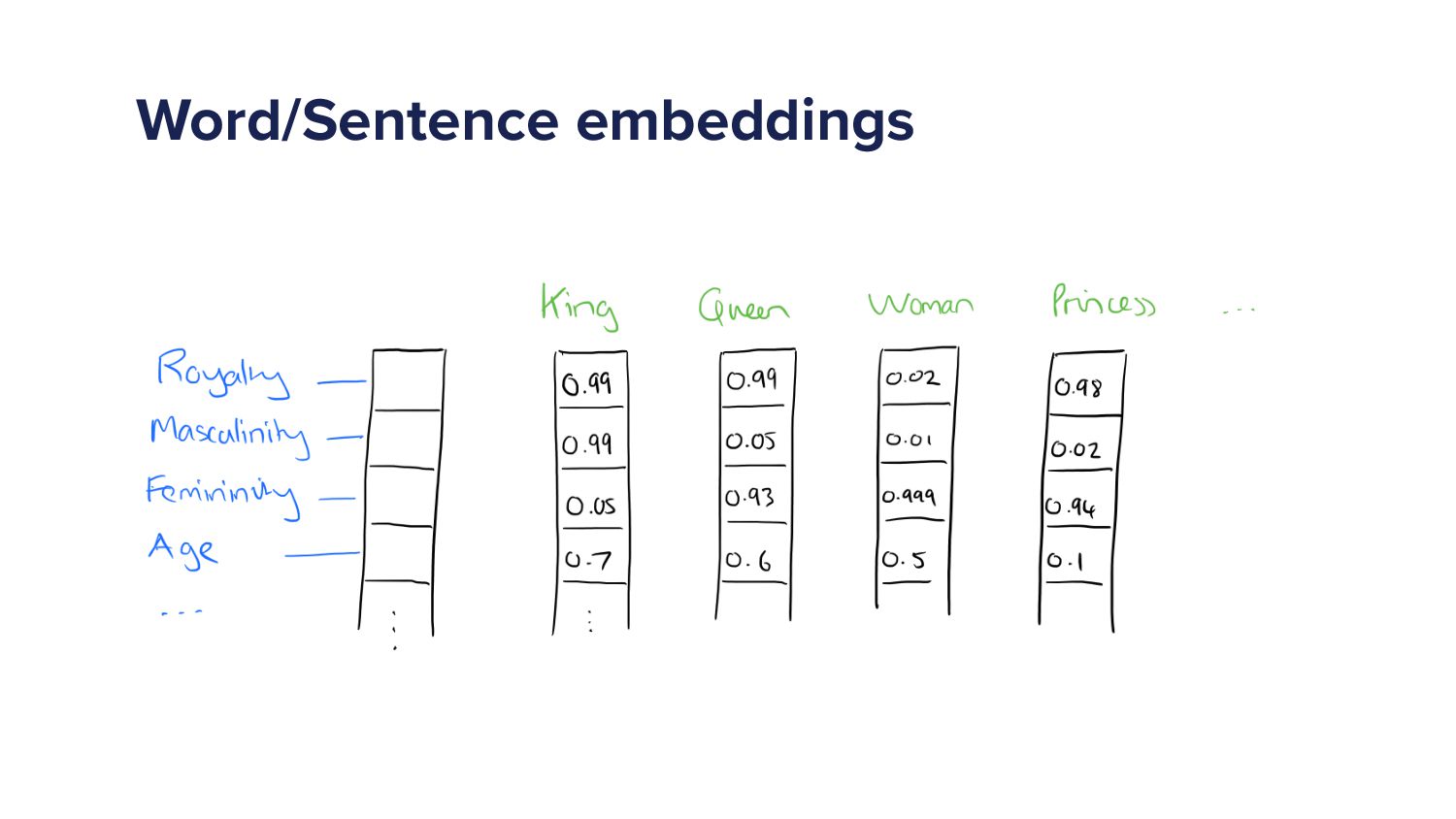
So we're using this stuff. So here's an example. Let's say I take the words in green at the top. So that I'm just gonna take the word king. Right? So you take the word king. What we want to do, what an embedding is is just representing that word by a set of numbers.
Right, is you misrepresent by a set of numbers. Right? We, we represent our queries by a set of seven hundred and sixty eight numbers. Right? But you can choose how how many numbers. And each of those numbers has some sort of meaning. So the word in blue on the left hand side will represent what each of those numbers mean.
So on the left hand side, you've got royalty. So if I put those numbers and say those numbers, between zero and one, right, they have that range, then king is quite high in royalty. So it gets the score zero point nine nine. But let's say femininity, kings have, you know, been men mostly.
Almost all solely. So it's gonna get a low score for femininity, zero point zero five. Alright. So we can try and get some underlying meaning of what these words are with these embeddings. That's what we do. Now in reality, when we do this, we don't actually set what those definitions are.
We don't set those blue words. What we do is we go and tell this, algorithm, this machine learning model to go and just figure it out you make up some random definition, you make up some random definition, you gotta do your thing, right?
Come up with some numbers, and then what we'll do is we'll have a look at those sets of numbers, right, for each word. Right? So we have a set of numbers, as I said, we're doing it for entire queries. We have seven hundred and sixty eight numbers.
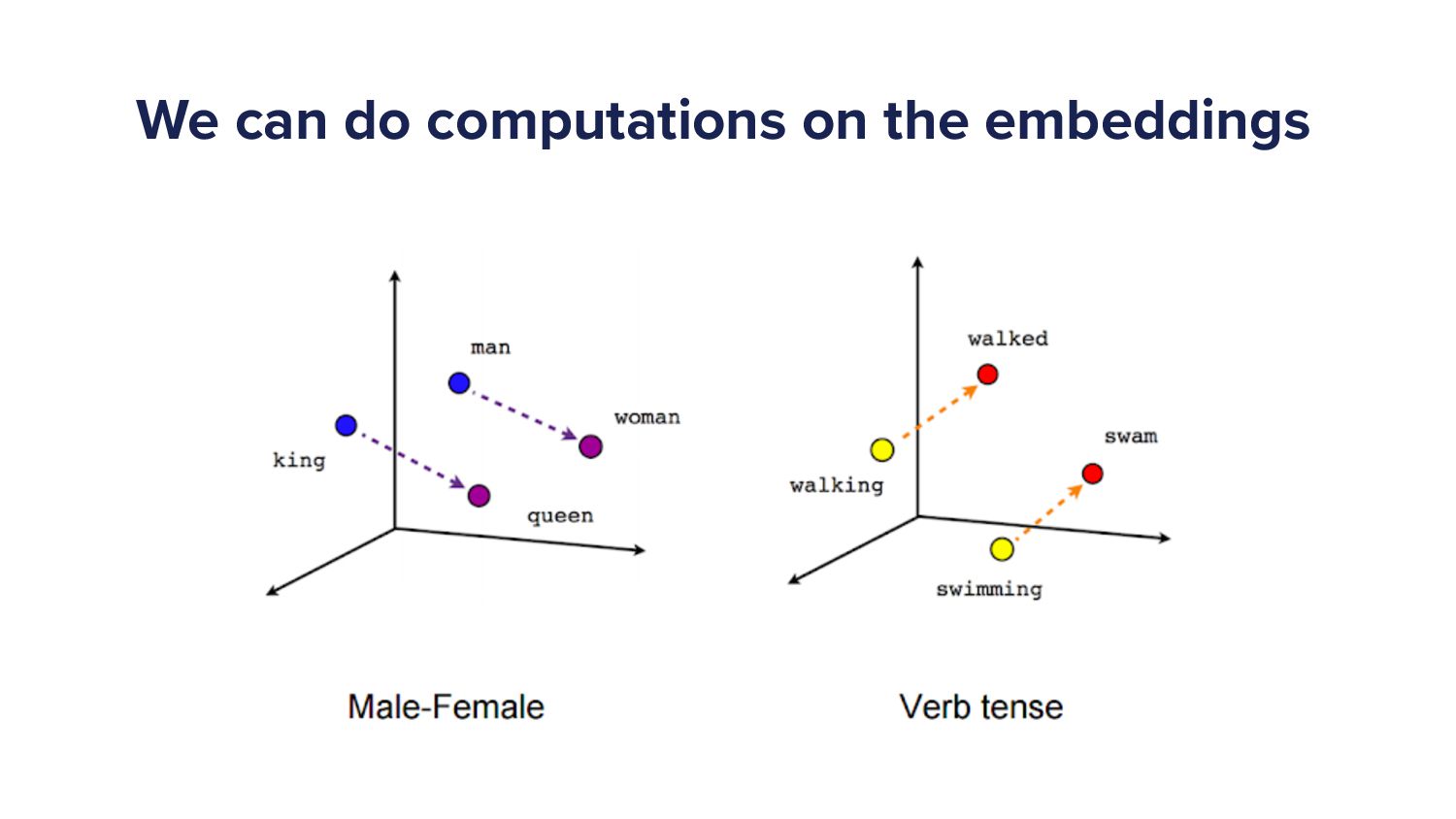
We'll go back and we'll say, okay. Now that we're represented by a set of numbers, we can just do maths on this. We can add numbers together. Right? We can dev we can divide them. But most importantly, we can actually work out how far away they must be.
So if you have two sets of numbers in mathematics, you can work out how far away two sets of numbers are. We call them distance measures or metrics. So what we can do is we can work out the difference between, say, king and queen is roughly the same difference between man and woman.
So what this actually ends up being is we can get some, understanding about these words in that vector space, in that set of numbers, in that vector space, we call it. And if they line up, then it means that they it must mean something.
The computer doesn't really know what it means. All it knows is that mathematically, they must do the, like, similar things. They have, like, somewhat, separate distances to each other. So what we did this, we trained the model. Right? So that the what we previously had was was, what I showed was were examples for single words, but we did this with Spotify queries, right?
We did it with queries, and then we also got our episodes. We got our podcast episodes. Right? Took all the metadata and the description and represented those by seven hundred and sixty eight numbers. And then we could take your queries. So at the top there, we got a query like tips for ending bad friendships.
And then we looked at what podcast episodes were close in space to that. And so you can see that we have how to know if your friendships are toxic. Five signs your friendship is ending, and things like that. So we started to see that we could represent queries and our documents in the same space, and they started to understand each other.
They started to learn things. And so we trained a machine learning model to do this, What I've done because, yeah, two and a half minutes left. Oh, damn. Yeah, I'm not gonna get through lessons learned all that much. I I got really excited at one point. It didn't happen.
What I've done is I've left links or you have the slides afterwards. I, I'm happy for you to have the slides. I've left links, to blogs that explain exactly how we did this. So the first one is our own internal blog post that we wrote about how this worked.
The second one was actually after we'd written the blog post, a guy not affiliated to Spotify, a different company, looked up red dot blog post and then re engineered what we'd done with open source data, and put the code up, and it's fantastic.
It's brilliant. So if you actually want to do this yourself, that second link there, go for it. What all means? It's brilliant. Yeah, if you want to do this stuff and and see if you can get it working on your own company's data, like, that is that is a link to go for.
But yeah, if you've seen me afterwards at the q and a, I'm I'm more than happy to give more details about how we how we did this. So yeah, the same thing happened. The same thing happened, guys. And this is important because we did this on top of crowd surf, so crowd surf was already working.
And then we released this one, and again, This one learned to to, like, show relevant podcasts and then what we did in April, so literally a few months, we then extended it to just all the entities. So now we took artist biographies and playlist descriptions and all that.
So now we can take a query and actually match it with the music as well. So you can do this with all of our all of our content in there. So, yeah, it's been brilliant. It it increased the amount of successful searches globally, and it's fantastic.
So also for our markets that aren't English speaking, so where tokenization doesn't work, for in the same in English in like countries like Japan, this has been fantastic. Because now we can get semantic understanding of Japanese, characters, and words, and and things like that.
So and it's not just Japan, any APAC country. So it's been fantastic for us. Yeah, I wanna breeze through this because I've got like eighteen seconds. But first thing I wanna say, don't just jump into Machine So this was the first thing, as I said, the crowd surface, not a machine learning model.
What you need to ask yourself whenever you get a problem is, how would I solve this without machine learning? Because the problem with machine learning is that it requires constant data, feedback loops, things you've got to maintain. So unless you've got a team that's able to maintain all that come all of those components, machine learning may not be the first thing to do.
So solve it without machine learning first. Second thing, Make sure you set up monitoring. Things can go wrong, and if you don't monitor it, then your users will tell you that things go wrong before you know they do. And that's not good for PR, at your company.
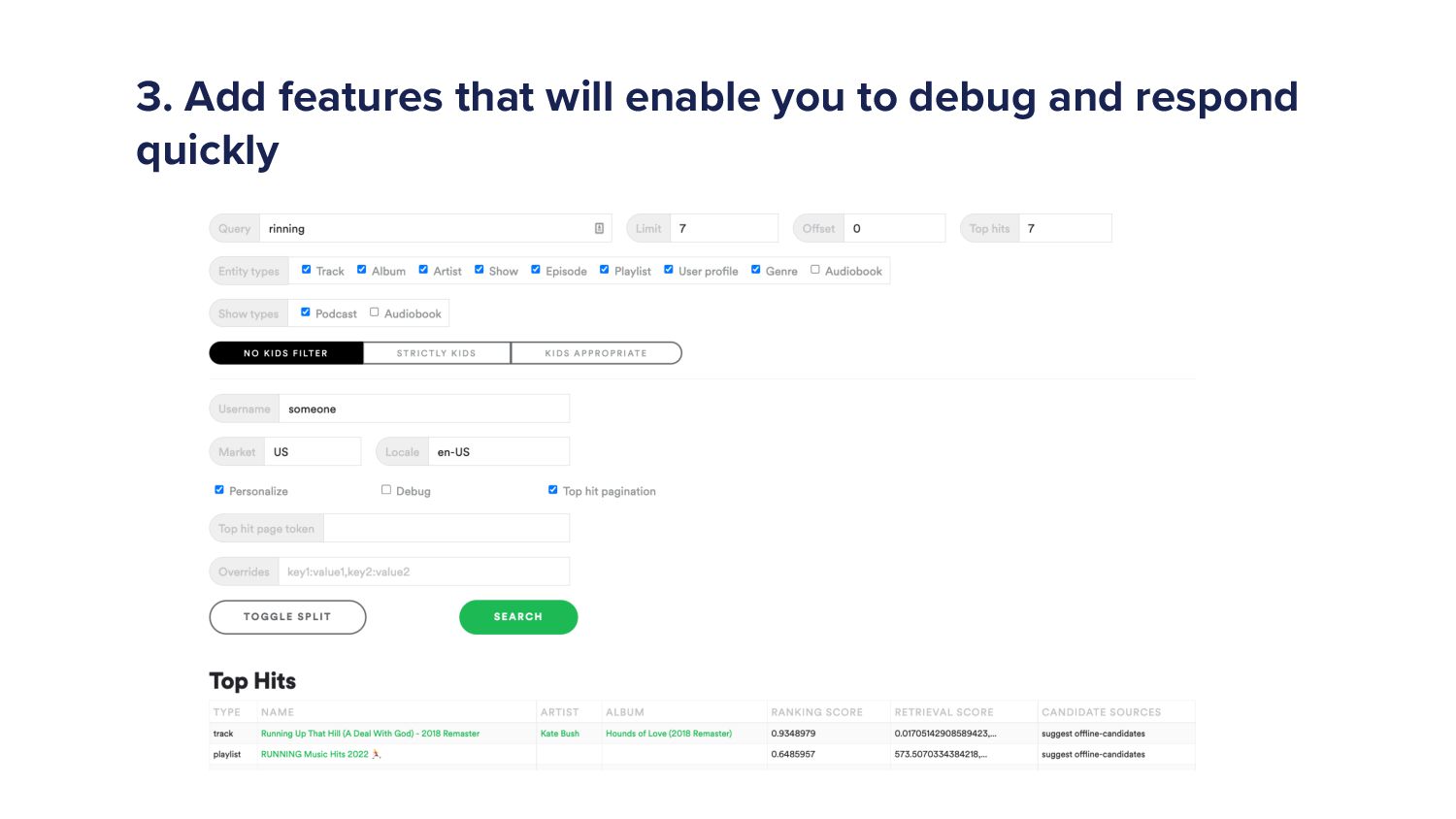
And then finally add tools to make it so that if there are problems, you can fix them quickly or you can debug and and reproduce the results. So we have this internal thing that we use to, like, copy and make sure that we can reproduce the user problems.
Right? And then it's done. So there we go. Wrapping up minus forty seconds. Alright. Search from, divide into three parts. This is what we learned. This is how search is set up. Any company. Right? This is how search it up. Right. Search can be hard. So it can be very hard.
But we built two systems to improve these things. And, well, we didn't really learn some lessons because I had to breathe through it, but we learned some lessons. Thank you guys.